
Flask招聘数据分析平台(BS架构)
一、项目背景
本项目基于BS架构构建
BS即Browser/Server(浏览器/服务器)结构,就是只安装维护一个服务器(Server),而客户端选用浏览器(Browse)运行软件。B/S结构应用程序相对于传统的C/S结构应用程序就是一个特别大的进步。
B/S结构的重要特征就是分布性强、维护方便、开发简单并且共享性强、总体拥有费用低。
随着互联网的普及和快速发展的高科技,互联网招聘在目前已经成为了一种主要的招聘方式,越来越多的求职者选择通过第三方招聘网站寻找工作,当然大多数企业也借助招聘网站发布招聘信息,从而吸引更多的优秀人才。互联网招聘给企业和求职者带来了新的机遇,但同时也给传统招聘方式带来挑战。本项目将针对互联网招聘的数据现状进行分析,并为高校毕业生提供就业市场招聘需求和行业趋势。
互联网招聘数据虚假信息比较多、信息较杂乱,毕业生难以获得全面且准确的就业信息,导致降低了求职效率。本项目选取BOOS直聘的各个城市的相关数据:职位名、公司位置、薪资、公司名称、工作经验、学历和公司类型等进清洗分析。
本项目通过使用Selenium爬虫爬取BOOS直聘网的数据,将爬取好的数据保存为CSV文件,添加表头、合并数据并另存,再将合并数据通过Navicatfor MysQL工具导入MySQL数据库中,然后利用Pandas、Numpy等进行数据清洗及数据分析,最后通过Flask +ECharts搭建可视化界面,将可视化分析结果展示出来。
二、技术架构
2.1 平台总体框架
本项目要实现的功能是通过交互式的数据分析大屏,可以根据不同的字段变化来显示不同的分析结果,与此同时可以输入学历、工作经验来预测出对应的薪资水平。招聘数据分析可视化大屏项目分为数据采集功能、数据清洗功能、数据存储功能、数据分析功能、薪资预测功能以及可视化功能等。

2.2 数据处理框架

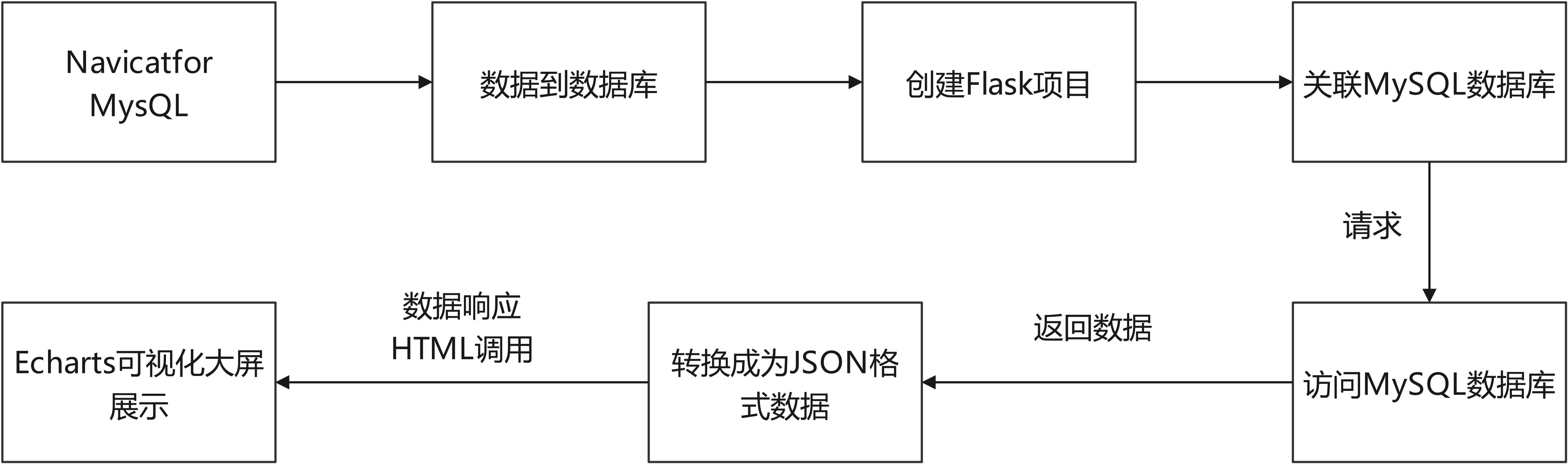
2.3 项目可视化框架

本项目基于BS架构构建,通过Selenium爬取BOOS直聘的数据存为CSV文件,并导入MySQL数据库中;再使用Python中的程序库进行数据的清洗和数据分析。后台采用Flask框架实现数据接口功能,并将MySQL数据库中数据响应至前端页面。前端主要采用HTML、CSS、JavaScript 、ECharts相结合,通过Flask 与 MySQL进行交互(Ajax请求),可在前端展示ECharts图表中的数据。
三、薪资预测功能
3.1 线性回归模型
线性回归模型试图找到一个最佳拟合直线,来近似表达预测变量与目标变量之间的线性关系。它的表达形式为

其中 是每个特征的变量,
是每个特征的变量, 是偏置常量,
是偏置常量, 是特征变量前的系数,
是特征变量前的系数, 是目标变量。线性回归模型通常用于预测数值型变量,例如,根据学历、工作经验等因素来预测薪资。该模型的优点是简单直观、易于理解和实现,但在某些情况下可能不适用于高度非线性的数据。
是目标变量。线性回归模型通常用于预测数值型变量,例如,根据学历、工作经验等因素来预测薪资。该模型的优点是简单直观、易于理解和实现,但在某些情况下可能不适用于高度非线性的数据。
首先导入相关包,读取数据集,打印输出前5行。并且对缺失值进行了处理。
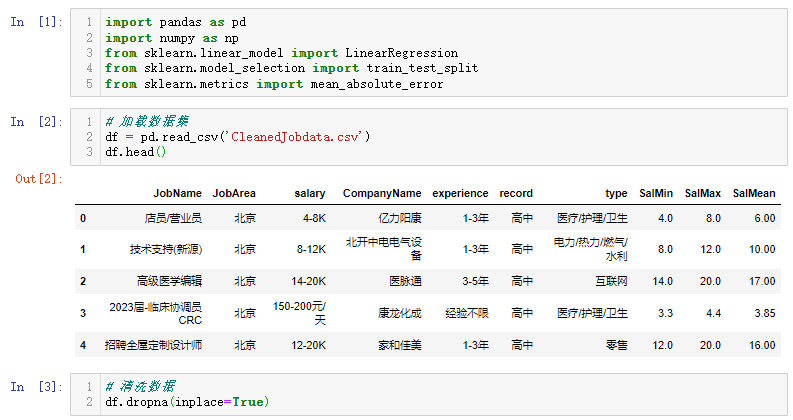
使用map函数将非数值数据转换为相应的数值,Record(学历)和experience(工作经验)将从非数值转换成数值型变量。“学历”列的数据已经做了预处理,其中1代表博士,2代表硕士,3代表本科,4代表大专,5代表高中,6代表学历不限,7代表初中及以下。“工作经验”列中1代表10年以上,2代表5-10年,3代表3-5年,4代表1-3年,5代表1年以内,6代表经验不限,7代表在校/应届。

由于其他变量的值太多所有选取这Record(学历)和experience(工作经验)两个变量为自变量,SalMean(平均薪资)为因变量。

模型的搭建,使用train_test_split函数将数据分割为训练集和测试集,然后,使用LinearRegression()函数训练模型。

模型的测试,使用predict函数进行预测。最后,使用mean_absolute_error函数计算预测结果与实际结果之间的平均绝对误差。

线性回归模型的平均绝对误差(MAE)为2.958,也就是说平均误差约为2.958k。
3.2 决策树模型
基尼系数(gini)是一种用于衡量数据集纯度的指标。在决策树算法中,基尼系数被用于评估每个候选特征的重要性,然后根据其大小来确定最佳的划分特征。基尼系数的计算公式如下:

其中 为类别
为类别 在样本
在样本 中出现的频率,即类别为
中出现的频率,即类别为 的样本占总样本个数的比率。基尼系数的计算公式也体现了这种思想,计算公式为对于每个类别,计算其出现的概率的平方之和并用1减去该值,最终将结果相加。通过计算基尼系数,可以选择哪个特征进行分裂来实现分类,从而构建决策树模型。
的样本占总样本个数的比率。基尼系数的计算公式也体现了这种思想,计算公式为对于每个类别,计算其出现的概率的平方之和并用1减去该值,最终将结果相加。通过计算基尼系数,可以选择哪个特征进行分裂来实现分类,从而构建决策树模型。

薪资预测决策树的建树依据主要是将与薪资相关的特征(比如学历、工作经验等)作为决策树的节点,对不同的特征进行分裂,每个分裂会产生一棵子树。在树的每个节点上,选择一个最佳的划分特征,根据该特征中的取值将数据划分为不同的子节点,使得每个子节点内部的数据尽可能的相似,同时尽可能的与其它子节点的数据不同。通常,薪资预测决策树会以一定的标准(如信息增益、基尼不纯度等)检验每个划分特征的影响,选取最优的划分特征,对其进行划分,得到一个新的子节点,递归地进行以上步骤,直至所有叶子节点不再进行划分,形成一颗完整的决策树。最终,利用决策树对测试数据进行预测,找到测试样本所在的叶子节点,该叶子节点的平均薪资值即为预测薪资。 
决策树模型的平均绝对误差(MAE)为2.838,也就是说平均误差约为2.838k。相对线性回归模型要略好一些。
3.3 随机森林模型
随机森林是一种集成学习方法,主要基于决策树模型。它通过构建多棵决策树来进行预测,每棵决策树都是通过从原始数据集中随机抽取样本和特征,再用有放回地抽样的方式构建得到的。森林的概念表明随机森林模型由多个决策树组成,每个决策树都算作随机森林的一棵子树。对于一个新的样本,它将通过多个决策树来进行分类或回归,最后输出所有决策树输出结果的平均值或取众数作为随机森林的最终输出结果。


随机森林模型的平均绝对误差(MAE)为2.838,也就是说平均误差约为2.838k。相对决策树模型和线性回归模型要略好一些。所以在后续的可视化展示的薪资预测我将采用随机森林模型。
我们选用了线性回归模型、决策树模型、随机森林模型这三种模型来对我们的薪资进行预测通过比较模型的误差,最后通过对比选用了随机森林模型。
随机森林模型是一种集成学习方法,它通过构建多个决策树来提高预测的准确性。这种模型的优势在于它能够克服单个决策树容易过度拟合的问题,并通过集成多个模型的预测来提高整体的泛化能力。此外,随机森林模型还具有特征选择的能力,可以进一步提升模型的预测能力和可解释性。经过对比不同模型的性能指标,我们发现随机森林模型在预测薪资方面具有更高的精确度和更稳定的表现。通过这种模型,我们能够获得更准确的预测结果,并从中获得对于预测薪资的更深入理解。
3.4 随机森林模型的搭建与训练
我们使用的环境是Python3+JupyterNotebook的组合搭建。具体的训练过程如下:
- 导入相关模型包,读取数据集,打印输出前5行
使用map函数将非数值数据转换为相应的数值,Record和experience将从非数值转换成数值型变量。“Record”列的数据已经做了预处理,其中1代表博士,2代表硕士,3代表本科等。“experience”列中1代表10年以上,2代表5-10年等。
由于其他变量的值太多,所以选取这Record和experience两个变量为自变量,SalMean为因变量。
RandomForestRegressor()函数训练模型,并用fit()函数训练模型。

模型的测试,使用predict函数进行预测,使用mean_absolute_error函数计算预测结果与实际结果之间的平均绝对误差。
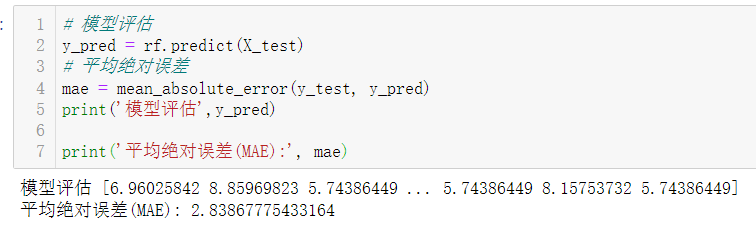
最后,我们用新的数据对模型进行预测,其中新数据中第一个元素5对应的是学历为高中,第二个元素4对应的是工作经验为1-3年。预测的薪资结果为:学历是高中的并拥有1-3年的工作经验薪资预测为6.37千元/月。

四、Flask项目的搭建
创建一个Flask项目,使用PyCharm创建的Flask项目的框架结构。该项目使用了Flask框架,通过创建app.py文件创建了一个应用程序实例,用于处理客户端的请求,前端页面由CSS样式和JS脚本组成的静态文件夹static和由html模板构成的模板文件夹templates组成,共同渲染页面。在Flask项目中使用render_template函数将先设计的页面模板index.html进行渲染。该项目的框架结构简单易懂,易于管理,并且可以根据需求快速扩展页面和功能,整个Fask项目框架如图所示。
第一部分,通过Flask框架的app.py来构建一个基础的Web应用程序实例。
第二部分,Flask框架实现路由和视图函数的业务逻辑。通过Flask程序实例,可以访问路由时执行的视图函数,从而实现每一个URL请求启动对应python函数的映射关系。项目实现所有URL请求调用的SQL方法的封装在opmysql.py中,如图所示。

第三部分,通过app.run()方法启动一个Flask Web应用程序。该方法可以在本地计算机或服务器上启动一个Flask应用,并监听HTTP请求,一旦接收到请求,服务器将会按照URL地址和HTTP请求方法进行路由转发。
五、数据可视化
可视化大屏的结构:统计分析一、统计分析二、就业创业政策、数据总览。

可视化大屏帮助高校毕业生了解就业市场的招聘需求和行业趋势,为他们提供求职技巧和就业技能方面的指导。例如,可通过数据分析和可视化展示对行业的招聘需求趋势和薪资水平变化等,从而帮助他们做出更为明智的求职决策。
薪资预测:用可视化大屏来展示随机森林模型预测的薪资结果。通过大屏,我们可以快速地呈现给用户更加直观的结果,帮助他们更好地理解随机森林模型的预测性能,并进行薪资预测。薪资预测模型的影响因素只有学历和工作经验,在实际应用中考虑的其他因素可能会更多,例如行业类型、公司规模、所在地区等,可以将更多影响因素添加到模型中,从而得到更加准确的预测结果。使用可视化大屏进行薪资预测时,我们可以在展示预测结果的同时,还可以使用可视化方式对各个影响因素的重要性进行分析,以便更好地辅助决策。

高校毕业生规模:随着国家经济和教育投入的提高,高校毕业生规模不断扩大,为各个行业和领域提供了更多的人才资源。但毕业生数量增多也带来了就业难度的增加,因此毕业生需要不断提升自己的专业水平,加强职业规划和发展,以适应就业市场的变化和提高自己的竞争力。同时在各方面也需要共同努力,注重就业培训和职业指导,加强就业政策的支持和保障,为毕业生提供更多的就业机会和保障,合理解决高校毕业生规模增长所带来的机遇和挑战。2001年至2023年(预计)高校毕业生规模

主要行业数据展示:通过分析知道在过去的几年对于培训、餐饮、旅游等行业是非常困难的,这些困难主要来自于市场竞争加剧、行业政策的变化等,所以在放开后培训、餐饮、零售、服务(旅游)行业迅速回升。


学历与薪资、工作经验的关系:学历与薪资的关系在不同的职业领域和不同的国家都可能有所不同,但一般情况下,学历确实会对薪资产生影响。一般来说,更高的学历可能会带来更高的薪资。但学历并不是唯一的因素,实际工作经验、技能水平、行业需求以及公司的薪酬政策等也会影响薪资水平。此外,对于某些行业和职位来说,拥有学位并不一定意味着能够获得更高的薪酬,而是需要其他的技能或经验。


薪资分布岗位分析:通过分析薪资的分布做了薪资分布,清晰的看到5-8K的月薪是最高的,一般情况高技能的职位薪资会相对较高,而低技能的职位薪资则会相对较低,对于岗位分析,我针对全国各地区发布的岗位平均薪资,清晰看到各地区的需求及均薪。


六、项目部署
本地文档:

在线地址:openEuler (22.03 (LTS-SP2) 部署BS架构项目


